"What’s Up, Doc?": Analyzing How Users Seek Health Information in Large-Scale Conversational AI Datasets
Akshay Paruchuri, Maryam Aziz, Rohit Vartak, and 5 more authors
In Findings of the Association for Computational Linguistics: EMNLP 2025, Nov 2025

People are increasingly seeking healthcare information from large language models (LLMs) via interactive chatbots, yet the nature and inherent risks of these conversations remain largely unexplored. In this paper, we filter large-scale conversational AI datasets to achieve HealthChat-11K, a curated dataset of 11K real-world conversations composed of 25K user messages. We use HealthChat-11K and a clinician-driven taxonomy for how users interact with LLMs when seeking healthcare information in order to systematically study user interactions across 21 distinct health specialties. Our analysis reveals insights into the nature of how and why users seek health information, such as common interactions, instances of incomplete context, affective behaviors, and interactions (e.g., leading questions) that can induce sycophancy, underscoring the need for improvements in the healthcare support capabilities of LLMs deployed as conversational AI. We release code and artifacts to retrieve our analyses and combine them into a curated dataset for further research.
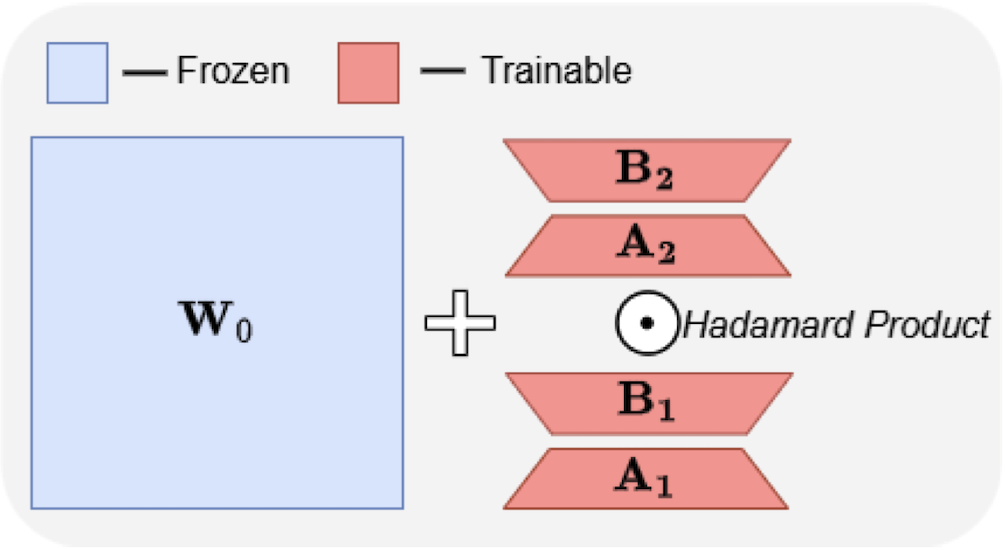 ABBA-Adapters: Efficient and Expressive Fine-Tuning of Foundation ModelsarXiv preprint arXiv:2505.14238Spotlight at ES-FOMO@ICML 2025, Accepted at ICLR 2026 , 2025
ABBA-Adapters: Efficient and Expressive Fine-Tuning of Foundation ModelsarXiv preprint arXiv:2505.14238Spotlight at ES-FOMO@ICML 2025, Accepted at ICLR 2026 , 2025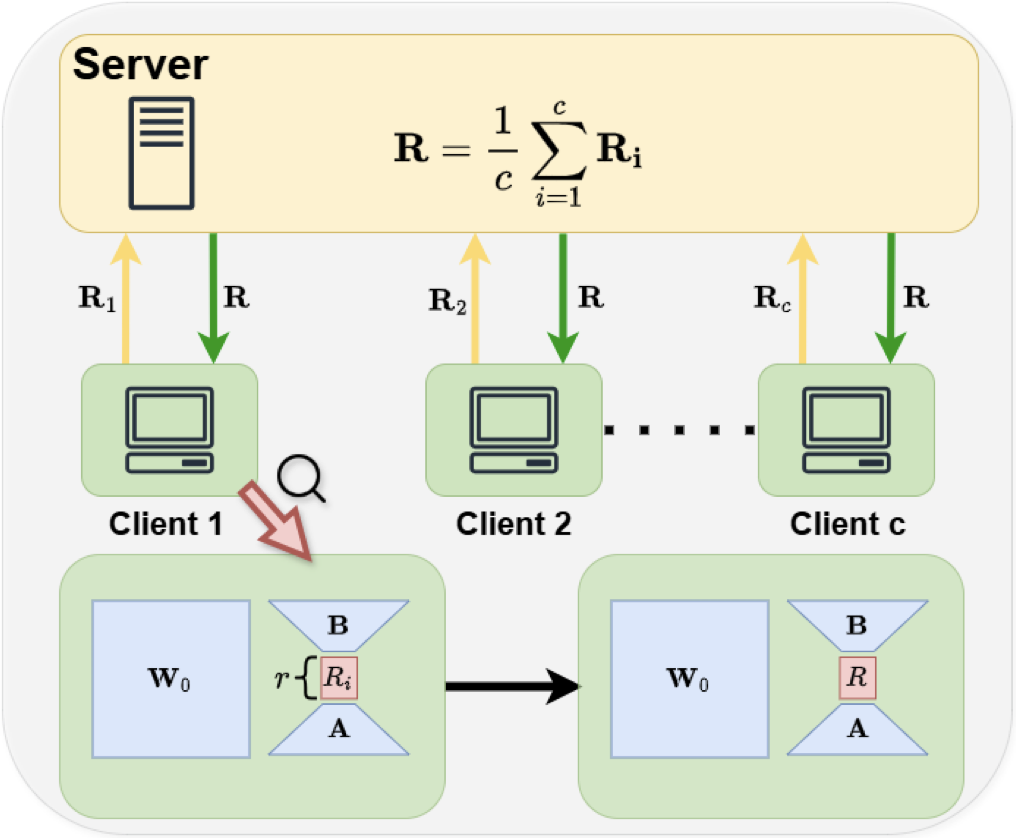 Fed-SB: A Silver Bullet for Extreme Communication Efficiency and Performance in (Private) Federated LoRA Fine-TuningarXiv preprint arXiv:2502.15436Accepted at ES-FOMO@ICML 2025 , 2025
Fed-SB: A Silver Bullet for Extreme Communication Efficiency and Performance in (Private) Federated LoRA Fine-TuningarXiv preprint arXiv:2502.15436Accepted at ES-FOMO@ICML 2025 , 2025