publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- "What’s Up, Doc?": Analyzing How Users Seek Health Information in Large-Scale Conversational AI DatasetsAkshay Paruchuri, Maryam Aziz, Rohit Vartak, and 5 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2025, Nov 2025
People are increasingly seeking healthcare information from large language models (LLMs) via interactive chatbots, yet the nature and inherent risks of these conversations remain largely unexplored. In this paper, we filter large-scale conversational AI datasets to achieve HealthChat-11K, a curated dataset of 11K real-world conversations composed of 25K user messages. We use HealthChat-11K and a clinician-driven taxonomy for how users interact with LLMs when seeking healthcare information in order to systematically study user interactions across 21 distinct health specialties. Our analysis reveals insights into the nature of how and why users seek health information, such as common interactions, instances of incomplete context, affective behaviors, and interactions (e.g., leading questions) that can induce sycophancy, underscoring the need for improvements in the healthcare support capabilities of LLMs deployed as conversational AI. We release code and artifacts to retrieve our analyses and combine them into a curated dataset for further research.
@inproceedings{paruchuri2025whats, title = {"What's Up, Doc?": Analyzing How Users Seek Health Information in Large-Scale Conversational {AI} Datasets}, author = {Paruchuri, Akshay and Aziz, Maryam and Vartak, Rohit and Ali, Ayman and Uchehara, Best and Liu, Xin and Chatterjee, Ishan and Agrawal, Monica}, editor = {Christodoulopoulos, Christos and Chakraborty, Tanmoy and Rose, Carolyn and Peng, Violet}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2025}, month = nov, year = {2025}, address = {Suzhou, China}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.findings-emnlp.125/}, doi = {10.18653/v1/2025.findings-emnlp.125}, pages = {2312--2336}, isbn = {979-8-89176-335-7}, } - ABBA-Adapters: Efficient and Expressive Fine-Tuning of Foundation ModelsRaghav Singhal*, Kaustubh Ponkshe*, Rohit Vartak*, and 1 more authorICLR 2026, Spotlight at ES-FOMO@ICML 2025 , 2025
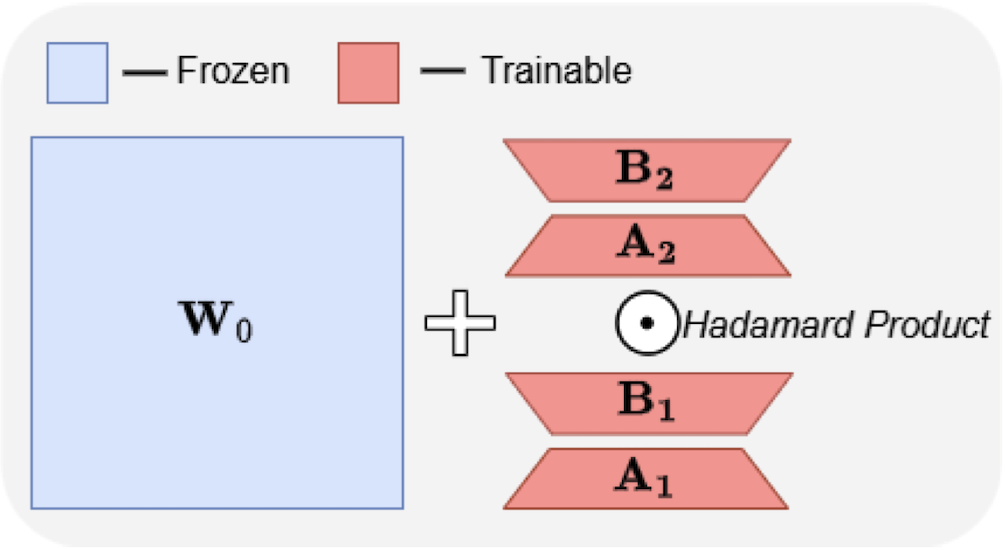
Large Language Models have demonstrated strong performance across a wide range of tasks, but adapting them efficiently to new domains remains a key challenge. Parameter-Efficient Fine-Tuning (PEFT) methods address this by introducing lightweight, trainable modules while keeping most pre-trained weights fixed. The prevailing approach, LoRA, models updates using a low-rank decomposition, but its expressivity is inherently constrained by the rank. Recent methods like HiRA aim to increase expressivity by incorporating a Hadamard product with the frozen weights, but still rely on the structure of the pre-trained model. We introduce ABBA, a new PEFT architecture that reparameterizes the update as a Hadamard product of two independently learnable low-rank matrices. In contrast to prior work, ABBA fully decouples the update from the pre-trained weights, enabling both components to be optimized freely. This leads to significantly higher expressivity under the same parameter budget, a property we validate through matrix reconstruction experiments. Empirically, ABBA achieves state-of-the-art results on arithmetic and commonsense reasoning benchmarks, consistently outperforming existing PEFT methods by a significant margin across multiple models. Our code is publicly available at: [here](https://github.com/CERT-Lab/abba).
@article{singhal2025abba, title = {ABBA-Adapters: Efficient and Expressive Fine-Tuning of Foundation Models}, author = {Singhal, Raghav and Ponkshe, Kaustubh and Vartak, Rohit and Vepakomma, Praneeth}, journal = {ICLR 2026}, year = {2025}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2505.14238}, } - Fed-SB: A Silver Bullet for Extreme Communication Efficiency and Performance in (Private) Federated LoRA Fine-TuningRaghav Singhal*, Kaustubh Ponkshe*, Rohit Vartak, and 2 more authorsTMLR, J2C Certification (Top 10% of accepted papers) , 2025
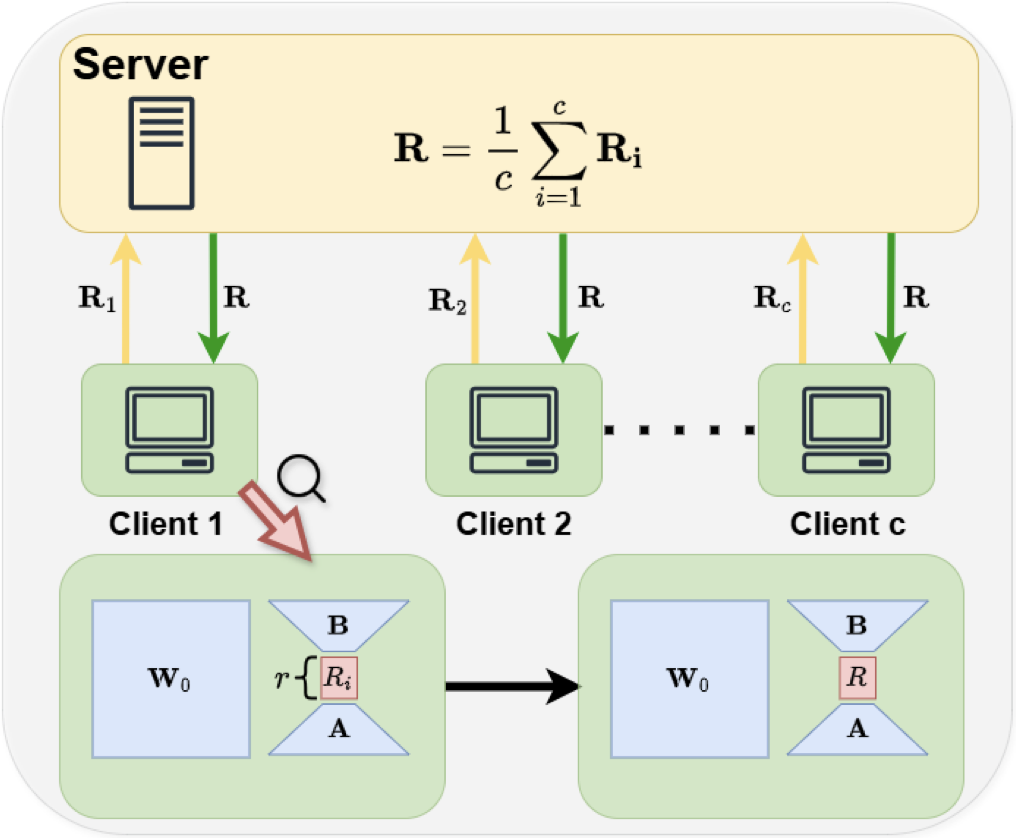
Low-Rank Adaptation (LoRA) has become ubiquitous for efficiently fine-tuning foundation models. However, federated fine-tuning using LoRA is challenging due to suboptimal updates arising from traditional federated averaging of individual adapters. Existing solutions either incur prohibitively high communication cost that scales linearly with the number of clients or suffer from performance degradation due to limited expressivity. We introduce Federated Silver Bullet (Fed-SB), a novel approach for federated fine-tuning of LLMs using LoRA-SB, a recently proposed low-rank adaptation method. LoRA-SB optimally aligns the optimization trajectory with the ideal low-rank full fine-tuning projection by learning a small square matrix (R) between adapters B and A, keeping other components fixed. Direct averaging of R guarantees exact updates, substantially reducing communication cost, which remains independent of the number of clients, and enables scalability. Fed-SB achieves state-of-the-art performance across commonsense reasoning, arithmetic reasoning, and language inference tasks while reducing communication costs by up to 230x. In private settings, Fed-SB further improves performance by (1) reducing trainable parameters, thereby lowering the noise required for differential privacy and (2) avoiding noise amplification introduced by other methods. Overall, Fed-SB offers a state-of-the-art, efficient, and scalable solution for both private and non-private federated fine-tuning. Our code is publicly available at: [here](https://github.com/CERT-Lab/fed-sb)
@article{singhal2025fedsb, title = {Fed-SB: A Silver Bullet for Extreme Communication Efficiency and Performance in (Private) Federated LoRA Fine-Tuning}, author = {Singhal, Raghav and Ponkshe, Kaustubh and Vartak, Rohit and Varshney, Lav R. and Vepakomma, Praneeth}, journal = {TMLR}, year = {2025}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, url = {https://arxiv.org/abs/2502.15436}, }

2023
- Robustness to Variability and Asymmetry of In-Memory On-Chip TrainingRohit K. Vartak, Vivek Saraswat, and Udayan GangulyIn Artificial Neural Networks and Machine Learning – ICANN 2023, 2023
In-memory on-chip learning is crucial for low-power, in-field training capabilities at the edge. We demonstrate the robustness of on-chip back-propagation to hardware variability in terms of bit-cell transistor V_T variability (2.5\times more robust than off-chip training). We use perturbation schemes, asymmetry variations and variability-aware update schemes to identify the relative contribution of different on-chip operations: forward pass, backward pass and weight updates to Fashion-MNIST classification performance degradation with variations. It is revealed that variability during the weight update step is crucial while accuracy of backward pass or gradient calculation is not critical. We promote weight perturbation scheme over back-propagation as the choice for on-chip in-memory training with reduced points of failure and low cost of hardware.